RabbitMQ高可用集群搭建
RabbitMQ + HAProxy 高可用镜像模式集群部署
本文介绍了如何搭建 RabbitMQ 高可用集群。首先介绍了部署说明和前提条件,然后详细介绍了集群模式和节点类型。接着介绍了环境准备和集群搭建的步骤,包括普通模式和镜像模式的配置。然后介绍了集群节点管理和故障处理的方法。最后介绍了使用 HAProxy 负载均衡的方法,并提供了安装、配置和验证的步骤。最后列举了一些常见问题。
RabbitMQ 高可用集群搭建
部署说明
下面将以一个示例说明多机部署一个高可用 RabbitMQ 集群的流程。
前提
在部署集群前,必须在将成为集群成员的每个节点上安装 RabbitMQ,并确保每个节点之间能相互访问。
RabbitMQ 集群模式
普通模式(默认的集群模式)
以两个节点 node1、node2 为例来进行说明。
对于 queue 来说,消息实体只存在于其中一个节点(node1 或 node2),node1 和 node2 两个节点仅有相同的元数据,即队列的结构。当消息进入 node1 节点的 queue 后,consumer 从 node2 节点消费时,RabbitMQ 会临时在 node1、node2 间进行消息传输,把 node1 中的消息实体取出并经过 node2 发送给 consumer。所以 consumer 应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理 queue。否则无论 consumer 连接 node1 或 node2,出口总在 node1,会产生瓶颈。
当 node1 节点故障后,node2 节点无法取到 node1 节点中还未消费的消息实体。如果做了消息持久化,那么得等 node1 节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢失的现象。
镜像模式
把需要的队列做成镜像队列,存在于多个节点,属于 RabbiMQ 的 HA 方案,在对业务可靠性要求较高的场合中比较适用。
该模式解决了普通模式中的问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用。
要实现镜像模式,需要先搭建一个普通集群模式,在这个模式的基础上再配置策略以实现高可用。
集群节点类型
- 内存(ram)节点
- 磁盘(disk)节点
RAM 节点仅将内部数据库表存储在 RAM 中。这不包括消息,消息存储索引,队列索引和其他节点状态。
在大多数情况下,您希望所有节点都是磁盘节点。 RAM 节点是一种特殊情况,可用于提高 queue、exchange 或 binding 流失率较高的群集的性能。 RAM 节点不提供更高的消息速率。如有疑问,请仅使用磁盘节点。
由于 RAM 节点仅将内部数据库表存储在RAM中,因此它们必须在启动时从对等节点同步它们。这意味着一个群集必须至少包含一个磁盘节点。因此,不可能手动删除集群中最后剩余的磁盘节点。
在 RabbitMQ 集群中,当磁盘节点宕掉且集群中无其他可用的磁盘节点时,集群将无法写入新的队列元数据信息。
环境准备
系统系统:CentOS7 64位
三台服务器:192.168.0.231/232/233
服务器规划
服务器 用途 主机名 节点类型 192.168.0.231 RabbitMQ 集群节点 1 node231 磁盘节点 192.168.0.232 RabbitMQ 集群节点 2 node232 磁盘节点 192.168.0.233 RabbitMQ 集群节点 3 node233 磁盘节点
集群搭建
普通模式
配置 hosts
vim /etc/hosts 编辑三个节点的 hosts 文件,在文件末尾添加如下内容:
1 | 192.168.0.231 node231 |
配置 hostname
node231
vim /etc/hostname编辑主机名如下:1
node231
vim /etc/sysconfig/network编辑网络配置文件,添加如下内容:1
2NETWORKING=yes
HOSTNAME=node231重启 network
1
systemctl restart network
node232
vim /etc/hostname编辑主机名如下:1
node232
vim /etc/sysconfig/network编辑网络配置文件,添加如下内容:1
2NETWORKING=yes
HOSTNAME=node232重启 network
1
systemctl restart network
node233
vim /etc/hostname编辑主机名如下:1
node233
vim /etc/sysconfig/network编辑网络配置文件,添加如下内容:1
2NETWORKING=yes
HOSTNAME=node233重启 network
1
systemctl restart network
配置 erlang cookie
RabbitMQ 集群是基于 erlang 进行同步的,在 erlang 的集群中各节点同步需要一个相同的 cookie,所以必须保证各节点 cookie 一致,不然节点之间就无法通信。这个 cookie 默认存放在 /var/lib/rabbitmq/.erlang.cookie 中。
在任意一个节点中 copy .erlang.cookie 文件到其它所有节点,如在 node1 上进行 copy :
1 | [root@node231 ~]# scp /var/lib/rabbitmq/.erlang.cookie root@192.168.0.232:/var/lib/rabbitmq/ |
重启节点
如果后面执行 rabbitmqctl stop_app 失败,需要重启 node231、node232、node233 使配置生效。
启动 rabbitmq-server
分别启动 node231、node232、node233 的 rabbitmq-server:
1 | [root@node231 ~]# systemctl start rabbitmq-server |
将节点加入集群
将 node232、node233 节点加入 node231 节点集群中,在 node232、node233 中分别执行以下命令:
1 | rabbitmqctl stop_app |
默认 RabbitMQ 启动后是磁盘节点,在这个 cluster 下,node231、node232 和 node233 都是是磁盘节点。
如果要使 node232、node233 都是内存节点,加上
--ram参数即可,如rabbitmqctl join_cluster --ram rabbit@node232。如果想要更改节点类型,可以使用命令
rabbitmqctl change_cluster_node_type disc(ram),修改节点类型前需要先rabbitmqctl stop_app。(Note: disk and disc are used interchangeably)
查看集群状态
任意节点执行:
1 | rabbitmqctl cluster_status |
创建管理用户
如果在主机名变更前就已经创建过用户的,仍需要重新重新创建,因为主机名的变更,之前创建的用户无法登录 web 管理系统。
以下操作在 node231 下执行:
创建 vhost(可选,默认使用 "/" vhost)
这里创建一个 vhost 用于测试:
1
[root@node231 ~]# rabbitmqctl add_vhost testvhost
创建用户
1
[root@node231 ~]# add_user admin password
设置用户角色
1
[root@node231 ~]# set_user_tags admin administrator
设置用户权限
1
[root@node231 ~]# set_permissions -p testvhost admin ".*" ".*" ".*"
启用 rabbitmq management
在 node231 上启用 rabbitmq management
1 | [root@node231 ~]# rabbitmq-plugins enable rabbitmq_management |
在浏览器中访问 http://192.168.0.231:15672,使用 "admin/password" 即可登录。
镜像模式
上面已经完成 RabbitMQ 默认集群模式,但并不保证队列的高可用性,尽管 Exchanges、Bindings 这些可以复制到集群里的任何一个节点,但是队列内容不会复制。所以集群中的节点宕机后将直接导致队列无法应用或消息丢失,要想队列在节点宕机或故障时也能正常应用,需要复制队列内容到集群中的每个节点,这就要使用镜像队列了。
为了确认队列内容默认不会复制,我们需要做些实验。
首先我们在 node231 节点上创建一个名为
demo_task的持久化队列(相关的 exchange 也是持久化的),这事可以看到队列的元信息会立即同步到 node232 和 node233 上。然后我们连接到 node231 节点上发布一个消息,发布成功后,你可以在所有节点上获取到该消息。
然后我们使用
systemctl stop rabbitmq-server命令将 node231 节点关闭,此时发现 node232 和 node233 虽然还保留了demo_task的元信息,但却无法从中获取消息了。
当我们使用
systemctl start rabbitmq-server命令再次将 node231 节点启动后,node232 和 node233 依然能看到 node231 关闭前已经持久化的消息。
镜像队列
默认情况下,RabbitMQ 集群中 queue 的内容位于单个节点(声明该 queue 的节点)上。这与 exchanges 和 bindings 相反,exchanges 和 bindings 始终可以被视为在所有节点上。可以选择使 queue 跨多个节点进行镜像。
每个镜像队列由一个 master 和一个或多个镜像(mirrors)组成。master 托管在一个通常称为主节点的节点上。每个队列都有其自己的主节点。给定队列的所有操作都首先应用于队列的主节点,然后传播到镜像节点。这涉及排队发布,向消费者传递消息,跟踪来自消费者的确认等。
队列镜像意味着节点的集群。发布到队列的消息将复制到所有镜像。无论消费者连接到哪个节点,最终都会被连接到主节点,镜像节点都会丢弃已在主节点上确认的消息。因此,队列镜像可提高可用性,但不会在节点之间分配负载(所有参与的节点均完成所有工作)。
如果承载队列主节点发生故障,则最早的镜像将在同步后提升为新的主节点。根据队列镜像参数,也可以升级不同步的镜像。
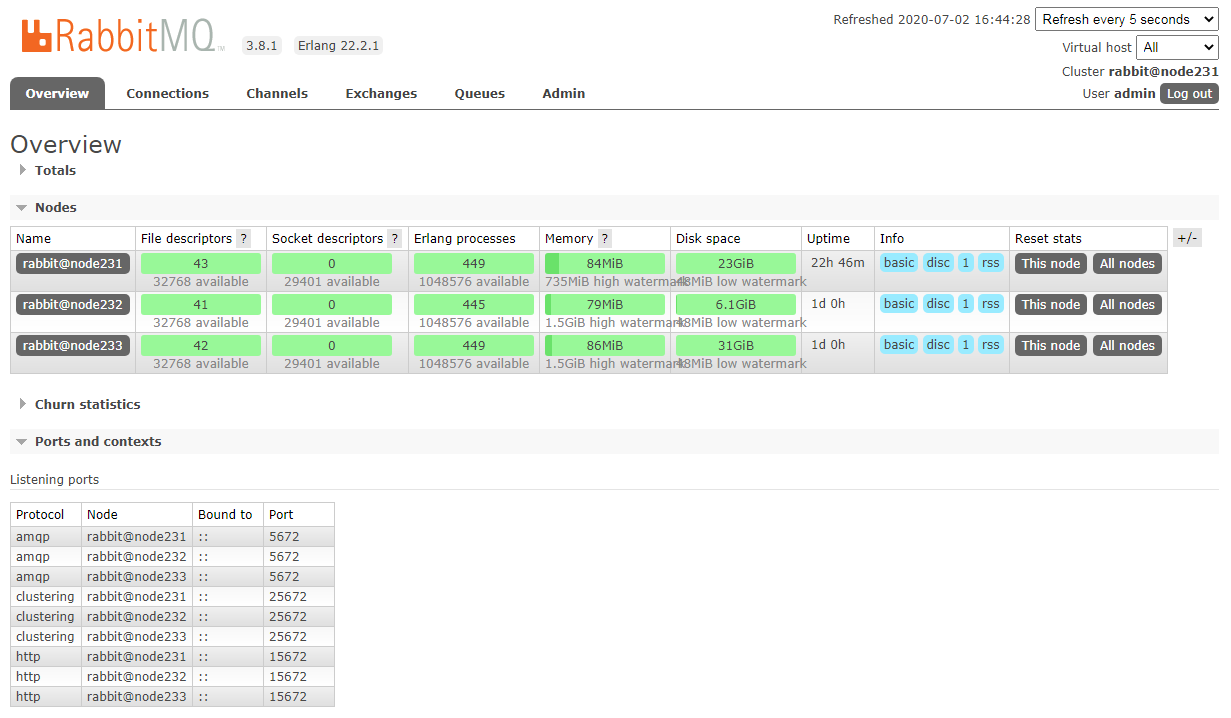
配置镜像策略
使用策略(policiy)配置镜像参数。 一个策略按名称(使用正则表达式模式)匹配一个或多个队列,并且包含一个定义(可选参数的映射),该定义被添加到匹配队列的全部属性中。
通过控制台添加策略
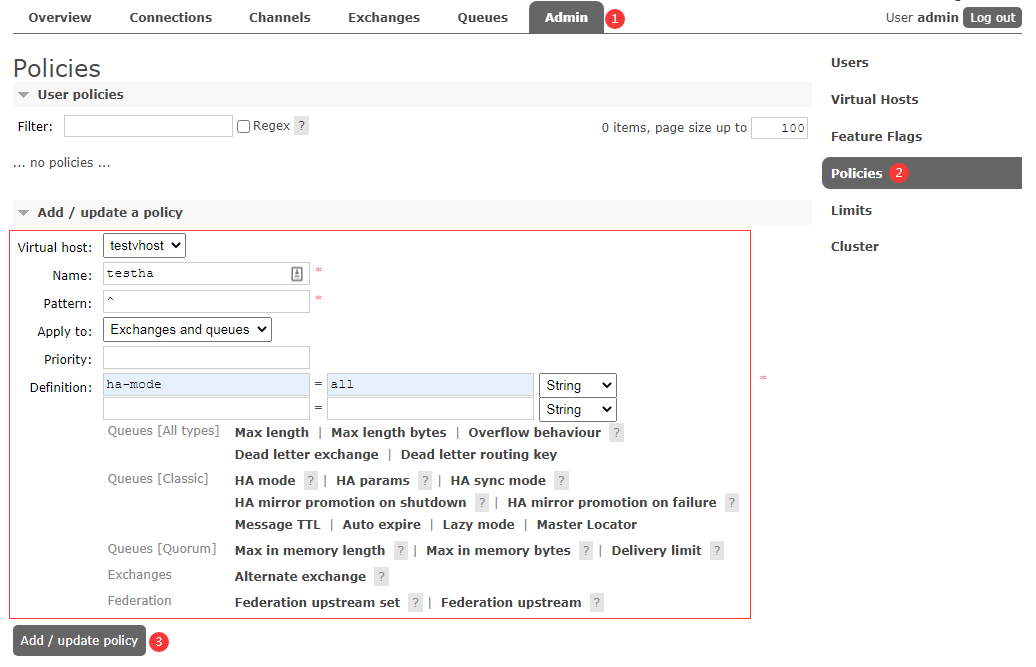
如果其他节点也启用了 rabbitmq_management,此时其他节点的控制台,可以看到上面添加的这个策略,如图所示:
参数说明:
Virtual host:策略应用的 vhost。
Name:为策略名称,可以是任何东西,但建议使用不带空格的基于ASCII的名称。
Pattern:与一个或多个 queue(exchange) 名称匹配的正则表达式,可以使用任何正则表达式。只有一个
^代表匹配所有,^test为匹配名称为 "test" 的 exchanges 或者 queue。Apply to:Pattern 应用对象。
Priority:配置了多个策略时候的优先级,值越大,优先级越高。
(没有指定优先级的消息会以0优先级对待。对于超过队列所定最大优先级的消息,优先级以最大优先级对待)
Definition:一组键/值对(例如 JSON 文档),将被插入匹配 queues and exchanges 的可选参数映射中
ha-mode:策略键,分为3种模式all- 所有(所有的 queue)exctly- 部分(需配置ha-params参数,此参数为 int 类型。比如 3,众多集群中的随机 3 台机器)nodes- 指定(需配置ha-params参数,此参数为数组类型。比如 ["rabbit@node2", "rabbit@node3"] 这样指定为 node2 与 node3 这两台机器)
ha-sync-mode:队列同步manual:手动(默认模式)。新的队列镜像将不会收到现有的消息,它只会接收新的消息automatic:自动同步。当一个新镜像加入时,队列会自动同步。队列同步是一个阻塞操作。
通过命令行添加策略
设置
1
rabbitmqctl set_policy [-p <vhost>] [--priority <priority>] [--apply-to <apply-to>] <name> <pattern> <definition>
清除
1
rabbitmqctl clear_policy [-p <vhost>] <name>
查看
1
rabbitmqctl list_policies [-p <vhost>]
例如:
1 | rabbitmqctl set_policy -p testvhost testha "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}' |
1 | rabbitmqctl list_policies -p testvhost |
1 | rabbitmqctl clear_policy -p testvhost testha |
测试策略是否生效
在控制台的队列页面上,镜像队列将展示策略名称和其他副本(镜像)数量。以下是一个名为 three_replicas 的队列的示例,该队列具有一个 master(主节点)和两个镜像节点。
添加队列:
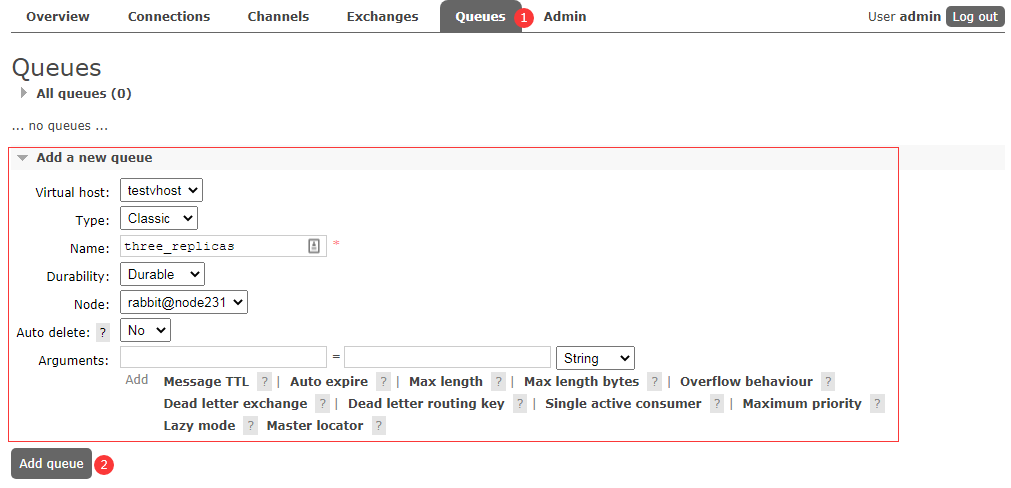
查看队列:


集群节点管理
故障节点重新加入集群
删除 /var/lib/rabbitmq/mnesia/ 下的数据,重新启动 rabbitmq-server,正常执行节点增加操作。
1 | rm -rf /var/lib/rabbitmq/mnesia/ |
节点增加
注:需要同步 .erlang.cooike 内容(.erlang.cooike 的权限为 400,所属者为 rabbitmq)
在需要加入的节点机器上执行:
1 | rabbitmqctl stop_app |
节点删除
正常删除
在需要删除的节点(rabbitmq-server 正常运行)机器上执行:
1 | rabbitmqctl stop_app |
硬删除
在集群正常节点将故障节点踢出,在其它正常的节点上执行(故障节点 rabbitmq-server 服务不可用):
1 | rabbitmqctl forget_cluster_node rabbit@node232 |
改变节点类型
disc -> ram
1 | rabbitmqctl stop_app |
ram -> disc
1 | rabbitmqctl stop_app |
HAProxy 负载均衡
HAProxy 是由 C 语言编写的免费的开源软件,它快速而高效,可为基于TCP和HTTP的应用程序提供高可用、高性能的负载平衡器和代理服务器。
环境准备
| 服务器 | 用途 | 系统 | 版本 |
|---|---|---|---|
| 192.168.0.235 | 负载均衡服务器 | Ubuntu 20.04 | haproxy 2.0 |
安装
Ubuntu
1 | sudo apt install haproxy |
CentOS 7
1 | wget http://www.haproxy.org/download/1.7/src/haproxy-1.7.12.tar.gz |
根据内核版本,选择编译参数
查看内核版本:
1 | [root@dev235 haproxy-1.7.12]# uname -r |
如:3.10.0-1127.19.1.el7.x86_64,此时该参数就为 linux310;kernel 大于 2.6.28 的可以用: TARGET=linux2628;
查看编译参数:
1 | [root@dev235 haproxy-1.7.12]# less README |
编译安装:
1 | make TARGET=linux310 ARCH=x86_64 PREFIX=/usr/local/haproxy |
TARGET=linux310,内核版本,如:3.10.0-1127.19.1.el7.x86_64,此时该参数就为linux310;kernel 大于 2.6.28 的可以用:TARGET=linux2628;ARCH=x86_64,系统位数;PREFIX=/usr/local/haprpxy,haproxy 安装路径;
使用 systemclt 管理 haproxy
在 haproxy-1.7.12 中有 systemd 脚本可以使用:
1 | [root@dev235 haproxy-1.7.12]# cat contrib/systemd/haproxy.service.in |
copy 到 /lib/systemd/system 下,并修改 @SBINDIR@ 为 /usr/local/haproxy/sbin,将 haproxy-systemd-wrapper 替换为 haproxy:
1 | cp contrib/systemd/haproxy.service.in /lib/systemd/system/haproxy.service |
配置
vim /etc/haproxy/haproxy.cfg 编辑 haproxy 配置文件,修改如下:
1 | global |
验证 HAProxy 配置
修改配置后,在启动 HAProxy 前,应先运行以下命令验证配置文件语法:
1 | haproxy -f /etc/haproxy/haproxy.cfg -c -V |
如果收到错误消息,请务必先修复,然后再继续。
运行 HAProxy
1 | systemctl restart haproxy |
查看状态:
1 | systemctl status haproxy |
HAProxy Statistics
浏览器访问 http://192.168.0.235:8888/stats,输入配置中的用户名和密码登录:
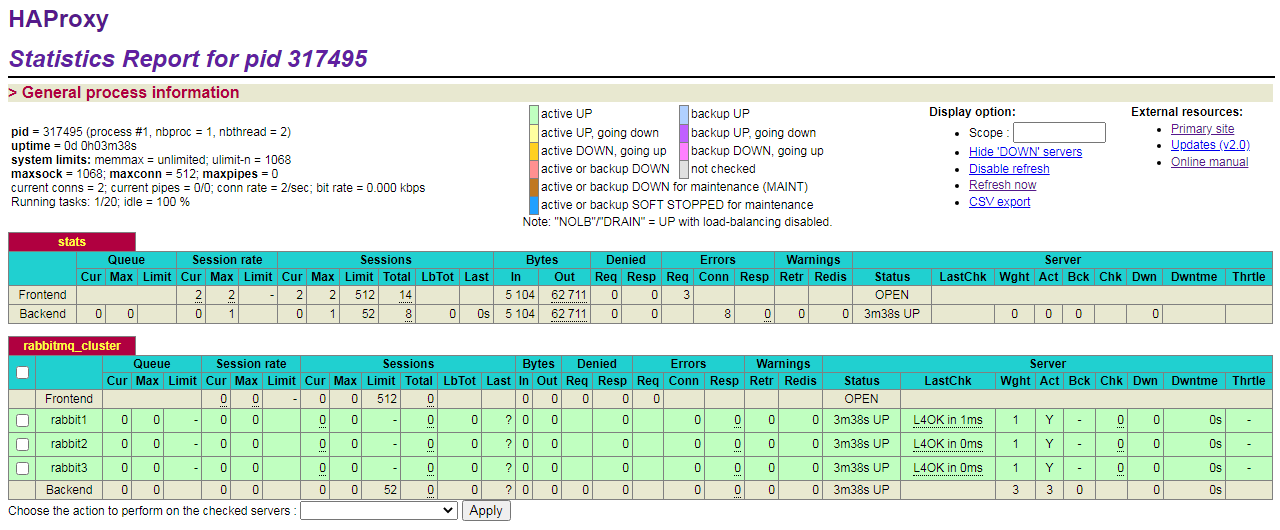
常见问题
1. 新节点 join_cluster 失败
问题描述:
新创建的 RabbitMQ 节点,在 join_cluster 时失败,提示如下信息:
1 | [root@node232 ~]# rabbitmqctl join_cluster rabbit@node231.com |
问题原因:
rabbit@hostname ,hostname 不允许包含 . 字符,如果主机名是 node231.com,则应该在 /etc/hosts 同时指定 node231 映射的 IP。
解决方法:
编辑
/etc/hosts文件,添加192.168.0.231 node231。使用
rabbit@node231而不是rabbit@node231.com。1
2
3
4
5[root@node232 ~]# rabbitmqctl join_cluster rabbit@node231
Clustering node rabbit@node232 with rabbit@node231
[root@node232 ~]# rabbitmqctl start_app
Starting node rabbit@node232 ...
completed with 3 plugins.查看集群状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51[root@node232 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@node232 ...
Basics
Cluster name: rabbit@node231
Disk Nodes
rabbit@node231
rabbit@node232
rabbit@node233
Running Nodes
rabbit@node231
rabbit@node232
rabbit@node233
Versions
rabbit@node231: RabbitMQ 3.8.1 on Erlang 22.2.1
rabbit@node232: RabbitMQ 3.8.1 on Erlang 22.2.1
rabbit@node233: RabbitMQ 3.8.1 on Erlang 23.2.3
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@node231, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@node231, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@node231, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@node232, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@node232, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@node232, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@node233, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@node233, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@node233, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Feature flags
Flag: drop_unroutable_metric, state: enabled
Flag: empty_basic_get_metric, state: enabled
Flag: implicit_default_bindings, state: enabled
Flag: quorum_queue, state: enabled
Flag: virtual_host_metadata, state: enabled
2. 'gzip' is not a supported algorithm
问题描述:
1 | [root@dev235 ~]# haproxy -f /etc/haproxy/haproxy.cfg |
问题原因:
Add zlib support in haproxy for compression offloading
解决方法:
This lies in script build-haproxy.sh, where adding USE_ZLIB=1 in the make stanza would do it.
重新编译安装
1 | make TARGET=linux310 ARCH=x86_64 PREFIX=/usr/local/haproxy USE_ZLIB=1 |
References
https://www.rabbitmq.com/clustering.html
https://www.rabbitmq.com/ha.html